

December 2023
5

November/December 2023 safety news: Weak-to-strong generalization, Superhuman concepts, Google-proof benchmark
newsletter.danielpaleka.com

October 2023
3

September/October 2023 safety news: Sparse autoencoders, A is B is not B is A, Image hijacks
newsletter.danielpaleka.com

August 2023
3

August 2023 safety news: Universal attacks, Influence functions, Problems with RLHF
newsletter.danielpaleka.com



July 2023
3

June/July 2023 safety news: Jailbreaks, Transformer Programs, Superalignment
newsletter.danielpaleka.com

June 2023

May 2023 safety news: Emergence, Activation engineering, GPT-4 explains GPT-2 neurons
newsletter.danielpaleka.com
3

April 2023
3

April 2023 safety news: Supervising AIs improving AIs, LLM memorization, OpinionQA
newsletter.danielpaleka.com

March 2023
1
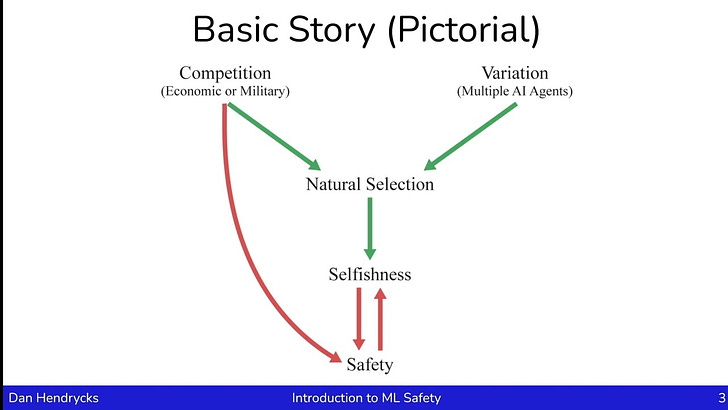
March 2023 safety news: Natural selection of AIs, Waluigis, Anthropic agenda
newsletter.danielpaleka.com


February 2023
2

February 2023 safety news: Unspeakable tokens, Bing/Sydney, Pretraining with human feedback
newsletter.danielpaleka.com

January 2023
2

January 2023 safety news: Watermarks, Memorization in Stable Diffusion, Inverse Scaling
newsletter.danielpaleka.com
