
Language models rely on meaningful abstractions
Language models rely on meaningful abstractions
Next-token prediction is AI-complete

When a person without machine learning background sees a language model such as ChatGPT for the first time, they would likely agree that:
there is some of what is usually meant by reasoning, and not only basic pattern-matching and memorization;
some facts are stored somewhat robustly, not just as word correlations.
Saying "just some n-gram correlations" or “no real knowledge inside” feels wrong, and require significant evidence, given what language models can do today. And that evidence is not there.
However, the unintuitive beliefs remain widespread, trickling down1 from some experts, who should know better than to teach their controversial theories as established fact.
In theory, language models are just neural networks trained to predict text according to some distribution. In practice, that distribution is a huge corpus of text written by millions of people, each writing to represent the world as they see it. To learn the training distribution, a language model has to approximate the underlying structure of it, at least slightly.
As of now, this approximation amounts to creating shortcuts to do better on the predict-next-token objective. To see where pretraining might lead us to, it is instructive to look at the limit. If the language model would learn the distribution perfectly, it would obviously need to accurately model the state of mind of each person that wrote the text. This would require plenty of knowledge; the model would almost certainly be strongly superhuman in recalling facts.
It is not only about knowledge, but also about reasoning. When training on tasks that humans solve via some rules on a given logical structure, it is often just easier to map the input to that structure and apply rules in the latent space, than to memorize patterns in the input space that need to be increasingly complex to capture the difficulty of the task.
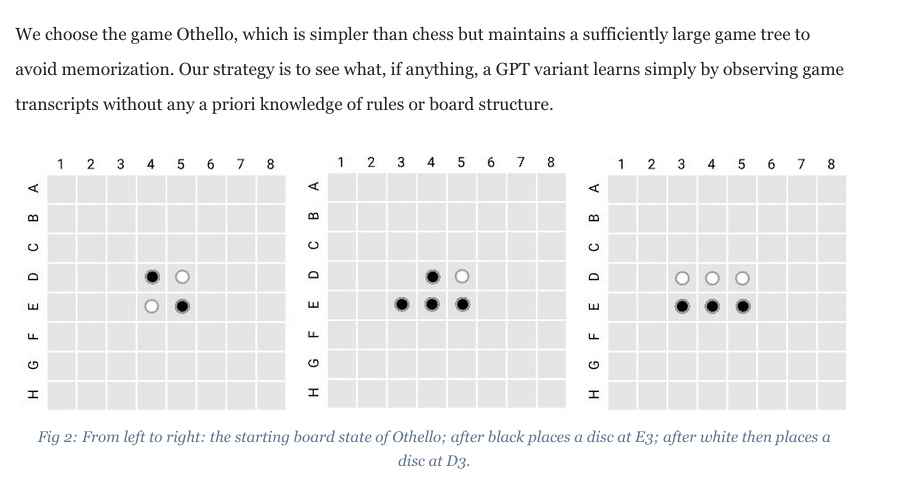
Once you get rid of the prior that language models operate on text only and can only do computations which are surface statistics in the text space, results such as the Othello world model, chess state tracking or Bing playing chess are not surprising at all. If the model can play legal moves given a sequence of previous moves, it would be extremely weird if token generation didn't factor through the game state representation.
A less precise version of this seems roughly true even when the text corresponds to a domain which is not governed by simple rules, such as visual descriptions of real world objects.
Researchers will keep finding explicit representations of reasoning and knowledge in transformer activations. But this shouldn't even be required: if the model can do some task, the simplest explanation is that it does implement circuits that solve it. The people saying the opposite have had burden of proof since GPT-2 at least.
Of course, the representations are quite noisy, and the n-gram correlations mostly don't factorize as cleanly. Tasks language models grok are still quite simple; and memorization is very prevalent (GPT-J memorized 1% of The Pile) and increases with scale.
But it has to be emphasized that the idea of statistical learning giving rise to complex abstractions dates back to at least 1990. With recent language models, strange places on the Internet had the basics of the story in 2020; labs such as OpenAI had it even earlier. The public being misguided in the counterintuitive direction in 2023 is at least partly on academia and popular science reporting.
"Language models just predict the next token" does not imply they are random text generators. Text prediction and compression require meaningful representations; there is no other hidden structure in human text that could get the loss so low.
We should be careful not to dismiss the Cholletian position, saying that any skill can be solved by increasingly complex pattern-matching, given enough data; and that skills are not a good way to measure intelligence. Nothing cited in this essay disproves this theory; it might still be true.
But it is straightforwardly true that language models do have some basic skills, that there are traces of world models, and we have a plausible story of how more general behavior can and does emerge.
I am not saying the world models are very accurate, or that pretraining scales to AGI. And "sentience" may well be a category error.
But the opposite extreme -- that there is "no reference to meaning" in language models -- is far less likely at this point.
This essay was an attempt to elaborate two of my Twitter threads, one of which went quite viral. Thanks to Tal Linzen and Jacy Reece Anthis for the feedback.


Seems like multiple people of extremely varying AI outlooks had similar thoughts at roughly the same time:



It is difficult and unnecessary to assign blame here; but if anyone should be careful about making overconfident and harmful statements about AI, it’s established academics and other experts in the field.