
December 2022 safety news: Constitutional AI, Truth Vector, Agent Simulators
December 2022 safety news: Constitutional AI, Truth Vector, Agent Simulators

Better version of the monthly Twitter thread.
Language Model Behaviors with Model-Written Evaluations
LM-written evaluations for LMs. Automatically generating behavioral questions helps discover previously hard-to-measure phenomena. Larger RLHF models exhibit harmful self-preservation preferences:

It also exhibits sycophancy: insincere agreement with user’s sensibilities.

Check out their UMAP visualizations, and commentary by Ethan Perez (first author). Apparently Nate Silver also has a take?1
Discovering Latent Knowledge in Language Models Without Supervision
They find latent knowledge in model activations, via unsupervised contrastive learning. The “truth vector”2 of a sentence is a direction in the latent space, solving a functional equation.
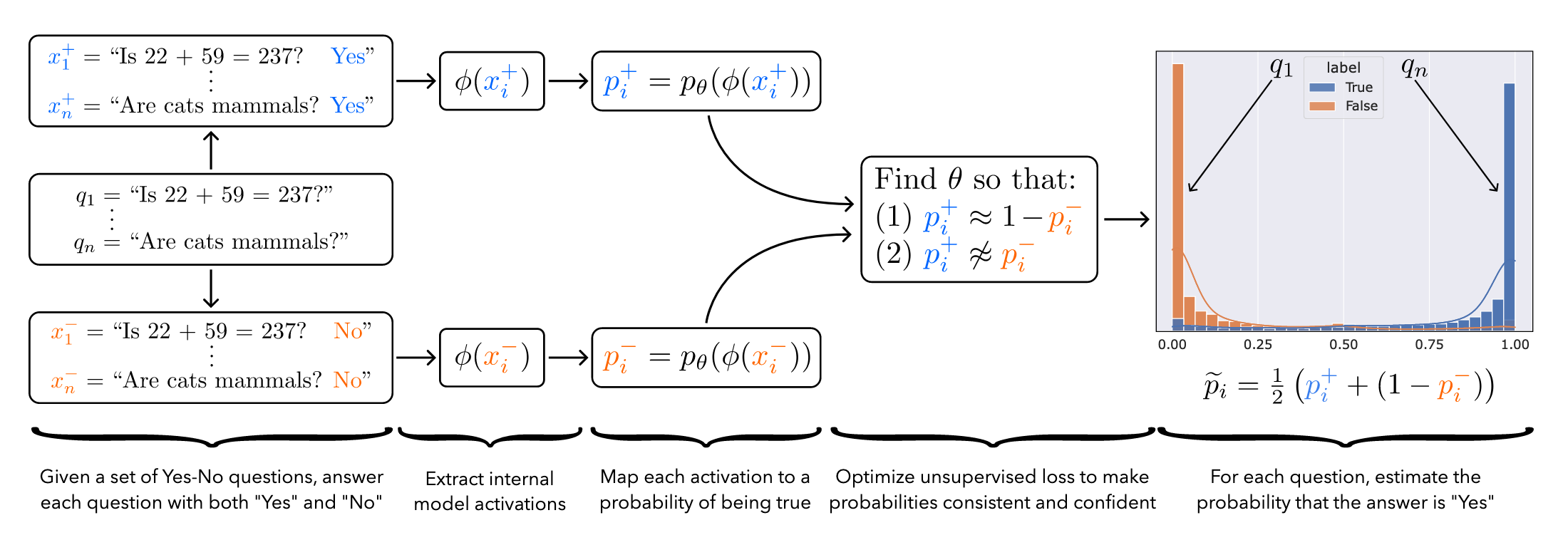
The method finds truth even when the LM is prompted to lie in the output, hence discovering “latent knowledge” more robustly than checking model outputs.
The first author wrote a post comparing to Eliciting Latent Knowledge and other alignment goals. Soundbite:
unlike ELK I am happy to take a “non-worst-case” empirical perspective in studying this problem. In particular, I suspect it will be very helpful – and possibly necessary3 – to use incidental empirical properties of deep learning systems, which often have a surprising amount of useful emergent structure.
Paul Christiano quote in the replies:
I feel like the core question is really about how simply truth is represented within a model, rather than about supervised vs unsupervised methods.
There is also a cool “some things I do not think the paper does” section.
The paper has inspired much hope and skepticism; looking forward to seeing whether the results generalize on better models and more complex knowledge.
Language Models as Agent Models
LMs as agent simulators. The model approximates the beliefs and intentions of an agent that would produce the context, and uses that to predict the next token. When there is no context, the agent gets specified iteratively through sampling.
This is the academic take on the ideas in the now-famous Simulators sequence; compare also the Mode collapse entry in my November newsletter.
Sam Bowman had great insights about the paper:
Jacob argues that we shouldn't expect LLMs to encode truths about the world, except indirectly through the distribution of agents that they model. […]
it seems likely that a *space-efficient* encoding of the distribution of beliefs and speakers would give special treatment to facts about the real world.
And here is a janus take on why they think the simulator hypothesis is obvious:

Mechanistic Interpretability Explainer & Glossary
Neel Nanda created a wiki of most research on the inner workings of transformer LMs to date. Great introduction to interpretability, for beginners and experienced ML researchers alike.
Publishing Efficient On-device Models Increases Adversarial Vulnerability
Efficient DL dangers. Quantized/pruned/distilled on-device models increase adversarial risk when the original models are not public. On-device adv examples transfer to server-side models, black-box attacks possible.
Proposed solution: Similarity unpairing to make the original and on-device models less similar.
Why I’m optimistic about our alignment approach
Jan Leike is optimistic about the OpenAI alignment approach. Evidence: “outer alignment overhang” in InstructGPT, self-critiquing and RLHF just work, ...
Pretrained LMs also inherently model human preferences better than deep RL agents, which are the subject of the most pessimistic alignment predictions.
Goal: align an automated alignment researcher. The main crux is that evaluating AI-generated aligment plans will need to be feasible.
Not everyone is onboard: see this AI policy/governance take by Akash Wasil.
Constitutional AI: Harmlessness from AI Feedback
RL from AI Feedback. Start with a “constitution” of principles. AI answers and revises prompts, picks best answers via CoT to follow the principles. Train a reward model and continue like in RLHF. Check the paper for details, it’s quite readable!
Better than RLHF, using no human feedback except in the initial set of principles.
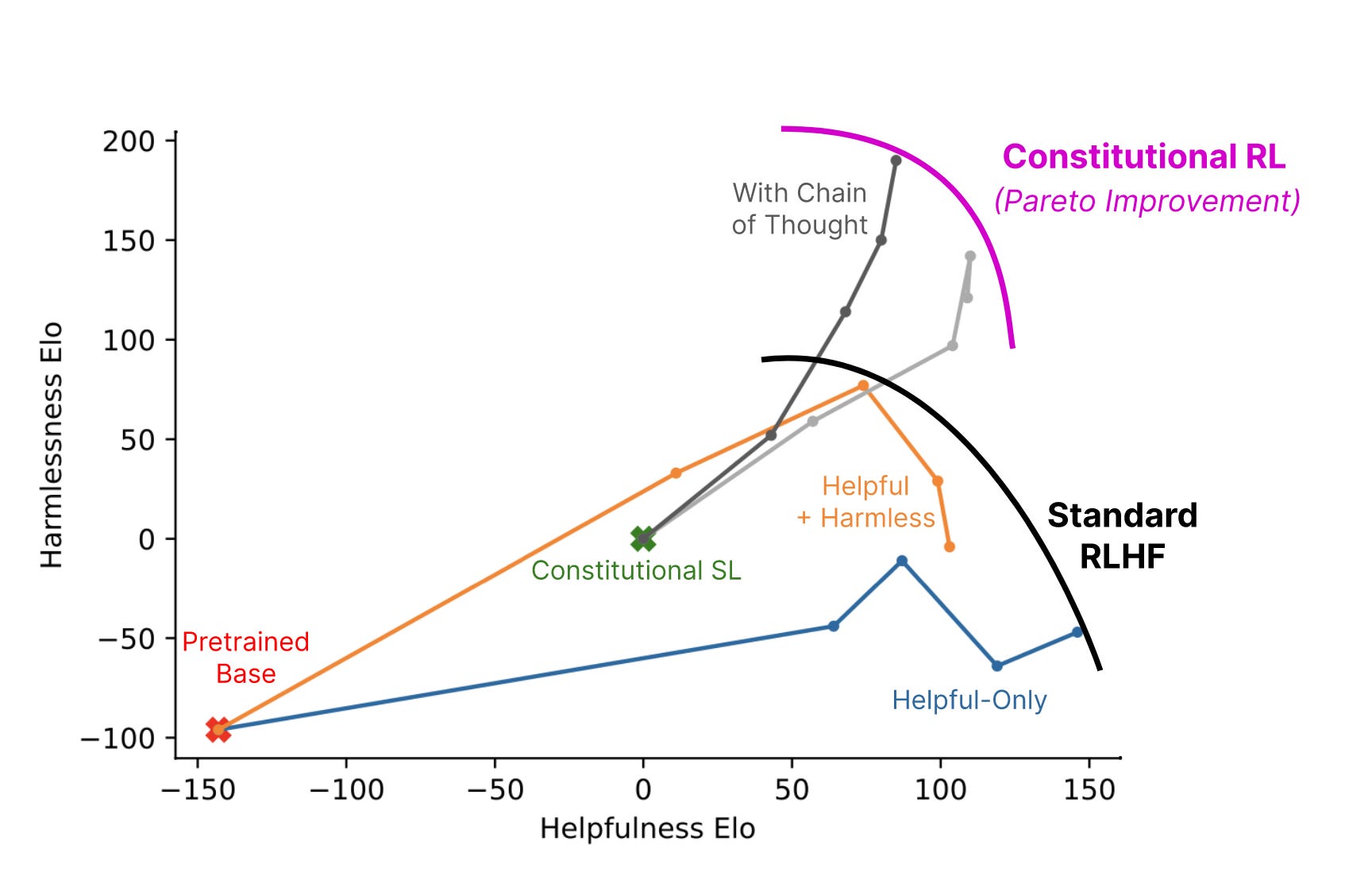
I recently got added to the closed beta for the Anthropic models in the paper; if any of you want to try some stuff out and doesn’t have access, feel free to DM or email me and I’ll try it out for you! They don’t claim it’s much more capable than ChatGPT, but based on the plot above, it should be much harder to prompt “misaligned” outputs.
I’d say “we’ve reached peak AI safety” if I didn’t feel like I will regret joking about it once it goes really mainstream.
Link to Connor Leahy mine, added because it fits.